

Hlášení o události: Výpadky v Evropě a Brazílii
Ahoj lidi, hlásí se Brian „Penrif“ Bossé z technologického oddělení League of Legends s podrobnostmi o technických potížích, které koncem února způsobily výpadky v EUW, EUNE a BR. Budu mluvit trochu jako nerd, ale pokud vás zajímají podrobnosti o těchto výpadcích a o tom, jak jsme je opravili, pojďte se se mnou vydat na výpravu plnou počítačů a grafů!
Nastínění problému
Prvním příznakem, který se dostal do hledáčku našeho centra síťových operací, bylo to, že počet zahajovaných zápasů v LoL drasticky klesl.
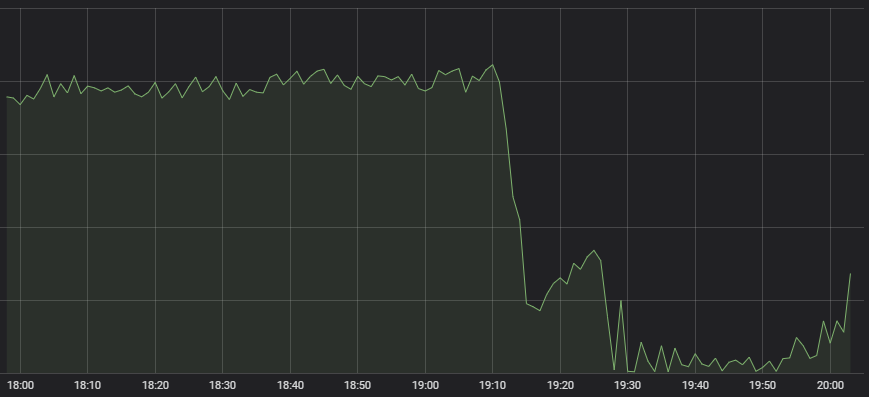
Tohle není obvyklé chování
Úspěšné vytvoření hry si žádá spoustu systémů od automatického sestavování zápasů přes distribuci zátěže až po samotné herní servery, takže z jednoho příznaku okamžitě nevyplývá, kde k problému došlo. Přizvali jsme experty na všechny tyto systémy, aby určili ohnisko problému. Všichni nám řekli, že stav služby vypadá v pořádku, ale že je na nich velmi nízký příchozí provoz. Automatický sestavovač zápasů, po kterém zápas žádá jen málo lidí, nemá moc co na práci.
Tohle všechno tedy poukazovalo na to, že máme co do činění se systémovou chybou, kvůli které se k nám nedostávají data od hráčů. Údaje v této oblasti naznačovaly velké problémy:
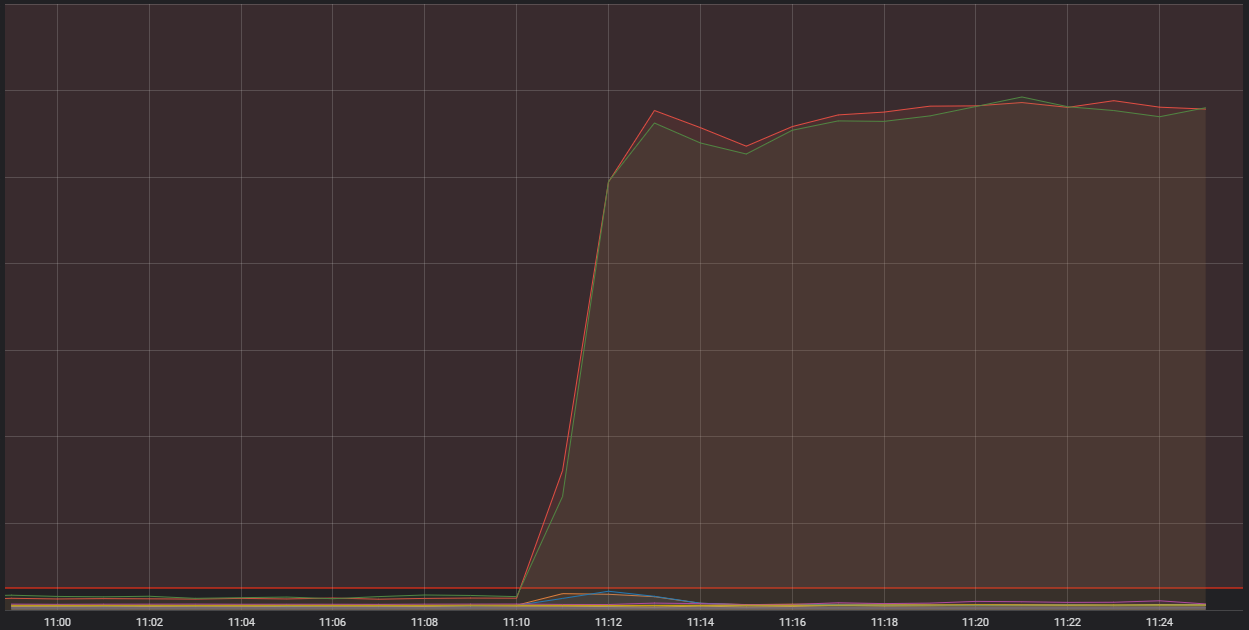
Horizontální červená čára úplně vespod představuje místo, kde se vyhlásí poplach
Tady vidíme počet příchozích připojení na jeden z našich generických hostitelských kontejnerů. To jsou vysoce výkonné a samostatné počítače, které řídí celou řadu menších aplikací (v obchodním jazyce – kontejnery), ze kterých se skládá celý systém, na kterém LoL běží. Na dva z těchto hostitelů chodí mnohem více připojení, než je rozumné. Abychom pochopili proč, musíme si popovídat o jednom speciálním kontejneru, který provádí funkci „na okraji“.
Život na okraji
Okrajové procesy mají za úkol sbírat provoz z internetu, filtrovat ho a přesměrovat ho na příslušnou službu na pozadí. Zpracovávají tu hromadu odpadků, kterou je veřejný internet, a nechávají ostatním jen hezký, čistý proud bajtů, který dokážou pohodlně zpracovat. Jak si dokážete představit, okrajové procesy třídí spoustu provozu, ale neměly by běžně vídat takový nárůst, který jsme zaznamenali během těchto událostí. Existují tři faktory, které této situaci předcházely; každý z nich popíšu v samostatné sekci a pak je spojím dohromady.
Tak to začalo
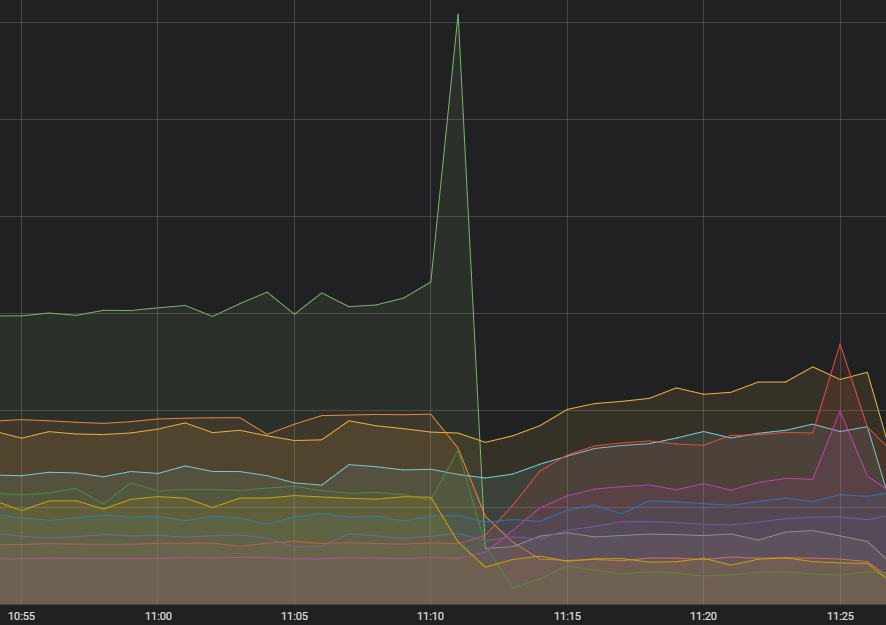
Nejdříve jiskra, která spustila celou tu kaskádu – nerozumný počet žádostí na jedné službě. Pár měsíců jsme zaznamenávali zvýšení nestability volací frekvence zaměřené na tuto službu, ale nezdálo se, že by to mělo nějaký dopad, a všechny systémy po proudu to v pohodě zvládaly. Diagnostikovat něco, co nikomu neubližuje, nám nepřišlo jako vysoká priorita pro aktivní zásah, ale okrajově jsme na to mysleli. Nyní jsme tu diagnózu ale provedli. Došlo k chybě v tom, jak se požadavek vytvářel, což v některých případech znamenalo, že vždy selhal – a vždy se opakoval.
Kontejnery spustily únik
Věděli jsme o problému, který se týkal interakce jednoho našeho kontejnerového systému s aktuální verzí operačního systému. Problém zahrnoval únik paměti do útrob operačního systému, což – po dostatečném čase, kdy mohl nabrat velkých rozměrů – mohlo zabrzdit kritické systémové funkce. Před touto událostí jsme ještě nikdy neviděli, že by k tomu došlo, ale stejně jsme vylepšili asi 60 % kontejnerové flotily Riotu. Aktualizace na evropských a latinskoamerických clusterech bohužel stále probíhala.
Na štěstí záleží
A nakonec jsme měli smůlu. Používáme jistý software pro řazení kontejnerů do skupin, které se vejdou na jeden hostitelský počítač. Má v sobě zabudovaná omezení, která tyto okrajové služby náročné na síť od sebe v rámci sady kontejnerů stejné oblasti oddělují. Nemohli jsme však ovládat, jestli mohou na stejném počítači skončit i okrajové služby z jiných oblastí, takže okrajové služby z EUW mohly skončit hned vedle okrajových služeb z EUNE. Toto násobení zátěže na jeden stroj udělalo z předchozích dvou problémů velkou mimořádnou událost.
V případě všech výpadků se okrajové kontejnery z alespoň tří oblastí ocitly na jednom hostiteli. Kvůli zvýšení provozu z poškozených požadavků, zesílenému tím, že na jednoho hostitele chodil provoz srovnatelný s několika oblastmi, a pak kvůli úniku paměti operačního systému, který stroj uvrhl do nefunkčního stavu, jsme zaznamenali zhroucení integrity oblasti a závažný výpadek.
Dopad a řešení
Rozmotat takový problém a najít izolované příčiny si obvykle žádá velké úsilí. Když jsme se museli rozhodnout, jestli budeme pokračovat v turnaji Clash na potenciálně nestabilním clusteru, měli jsme podezření, že problémy s kontejnerem byly klíčovou součástí potíží. Ještě jsme ale přesně nevěděli, jaký ten provoz vlastně je. Přestože turnaj Clash ten problém ani v nejmenším nezavinil, rozhodli jsme se ho o týden odložit, abychom měli jistotu, že zážitek s turnajem Clash ochráníme. Upřímně se omlouvám za narušení, které tyto události způsobily, a chci vás ujistit, že máme řešení pro každý aspekt, který k nim přispěl.

Kód, který způsoboval odesílání poškozených žádostí, byl opraven. A pro případ, že v budoucnu dojde k podobným problémům, jsme změnili způsob fungování opakovacího mechanismu, aby nedocházelo k velkým výkyvům. Vylepšení kontejnerového softwaru bylo dokončeno ve všech čtyřech oblastech. Máme konkrétní plány pro přesun okrajových služeb na vyvažovací systém, který je dokáže rozložit napříč oblastmi. Dokud tyto plány nedokončíme, máme aktivní poplašné hlášení, takže něčí telefon se promění v křičící naštvanou skříňku, dokud nedojde k ručnímu rozložení zátěže.
Věříme, že když jsme uvedené příčiny vyřešili, tento konkrétní problém se už nebude opakovat. Nicméně hru i její podpůrné systémy neustále rozvíjíme a podobné situace mohou nastat vždy. Pokud k tomu dojde, jsme připraveni službu obnovit co možná nejrychleji. Díky, že jste to dočetli až sem. Pokud vás podobný obsah zajímá, články s podrobnějším rozborem technologie LoL můžete najít na našem technickém blogu. Tak nebo tak se uvidíme ve Žlebu.
