
Informe de incidentes: cuelgues en Europa y Brasil
¡Hola! Soy Brian "Penrif" Bossé, del departamento de tecnología de League of Legends. Voy a compartir con vosotros detalles sobre los problemas técnicos que han causado los recientes cuelgues en EUW, EUNE y BR a finales de febrero. Me voy a poner en plan friki al respecto, pero, si tenéis curiosidad sobre los detalles relacionados con los cuelgues del juego y lo que hemos hecho para arreglarlos, ¡acompañadme en este viaje entre ordenadores y gráficos!
Preparando el escenario
El primer síntoma que llamó la atención de nuestro centro de operaciones de red fue que el número de partidas de League of Legends creadas disminuyó drásticamente.
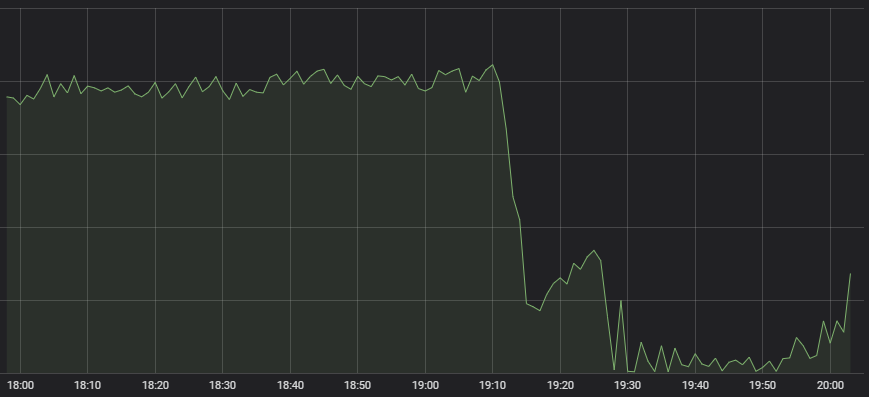
Comportamiento atípico
Hay muchos sistemas que influyen en la creación de una partida: el emparejamiento, la distribución de la carga o el servidor del juego en sí mismo, y no está claro desde el principio de dónde puede proceder un síntoma como este. Cuando hicimos venir a los expertos de cada uno de estos sistemas para que nos diesen su opinión, todos nos indicaron que la salud de sus servicios parecía estar en buen estado, pero que les llegaba muy poco tráfico. Un sistema de emparejamientos al que no llegan muchas personas no tiene mucho que hacer.
Por tanto, todo indicaba que nos estábamos enfrentando a un problema sistemático a la hora de conseguir tráfico de jugadores por nuestra parte. Las métricas nos mostraron grandes problemas al respecto:
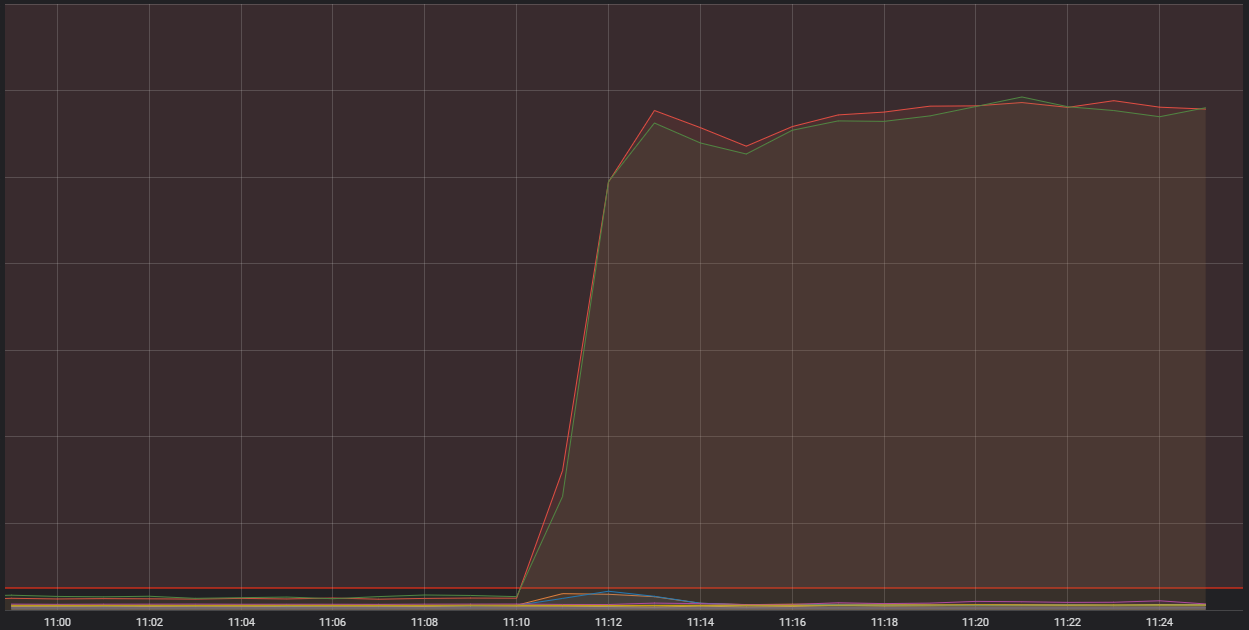
La línea roja horizontal de la parte inferior es la que hace saltar las alarmas.
Lo que se observa aquí es el número de conexiones entrantes en uno de nuestros servidores de contenedores genéricos. Se trata de ordenadores individuales muy potentes que ejecutan una serie de aplicaciones más pequeñas (es decir, contenedores) y que conforman el sistema general que hace funcionar League of Legends. Dos de esos contenedores están recibiendo muchas más conexiones de lo razonable. Para poder entender por qué, es necesario que hablemos sobre un tipo de contenedor en concreto, uno que realiza una función de "edge".
Al borde del abismo
Los procesos de edge se encargan de recoger tráfico de internet, filtrarlo y redirigirlo hasta el servicio de soporte correcto. Recogen toda la basura de la que está formado el internet público y dejan solo series de bytes limpias y ordenadas para que todos los demás las procesen sin problemas. Como ya os imaginaréis, los procesos de edge reciben mucho tráfico, pero no debería ser normal ver la subida que experimentamos durante estos eventos. Hay tres factores que se alinearon para crear esta situación. Hablaré de cada uno en una sección y, luego, lo uniré todo.
Y así empieza
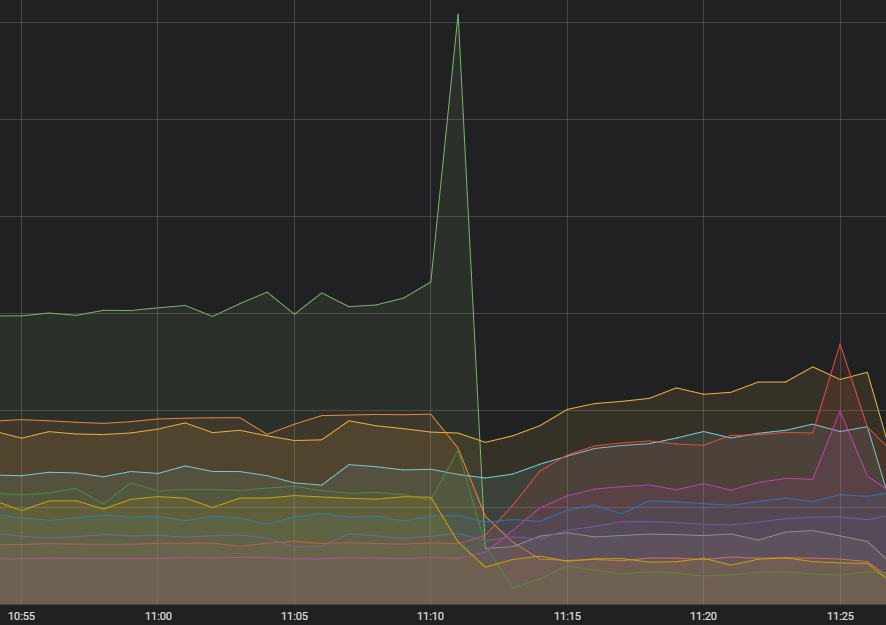
En primer lugar, la gota que colmó el vaso: una cantidad enorme de peticiones a un solo servicio. Durante unos meses, hemos notado un aumento en la volatilidad de la frecuencia de las llamadas dirigidas a dicho servicio, pero no parecía tener ningún impacto y todos los sistemas anteriores no habían tenido problemas con ello. Diagnosticar algo que no tenía ningún impacto no se clasificó como una prioridad para dedicarle un esfuerzo activo, pero lo mantuvimos presente. Sin embargo, lo habíamos diagnosticado. Había un error en la forma en la que se creaba la solicitud que, en ciertos casos, hacía que fallará constantemente y que se reintentará el mismo número de veces.
Hubo una fuga en los contenedores
Sabíamos de la existencia de un problema relacionado con la forma en la que interactuaban el sistema de contenedores y la versión del sistema operativo del momento. El problema tenía que ver con una fuga de memoria dentro de las entrañas del sistema operativo, lo que, con suficiente tiempo, podría detener funciones vitales del sistema. Nunca habíamos visto algo así antes de este evento, pero, de todos modos, ya habíamos actualizado alrededor del 60 % de la flota de contenedores de Riot. Por desgracia, la actualización de Europa y Latinoamérica todavía estaba en progreso.
Cuestión de suerte
Y, al fin y al cabo, no tuvimos suerte. Utilizamos un software que agrupa los contenedores en montones que puedan encajar en un solo ordenador del servidor. Tiene restricciones programadas para mantener estos servicios de edge centrados en la red separados entre sí dentro del mismo grupo de contenedores. Sin embargo, no podíamos controlar si los servicios de edge de diferentes grupos podrían acabar en el mismo ordenador, así que los servicios de edge de EUW podrían llegar a estar al lado de los servicios de edge de EUNE. Ese aumento de carga en una sola máquina actuó como una lupa que hizo crecer todavía más los otros dos problemas.
En todos los cuelgues, los contenedores de edge de al menos tres grupos se encontraban en un mismo servidor. Con un poco de tráfico de las solicitudes mal creadas amplificado al tener varios grupos de tráfico en el mismo servidor y, por otro lado, la fuga de memoria del sistema operativo haciendo que la máquina no funcionase, experimentamos una crisis en la integridad del grupo y un gran apagón de los servidores.
Impacto y resolución
Por lo general, hace falta un esfuerzo significativo para solucionar este tipo de problemas y encontrar causas aisladas. Cuando tuvimos que decidir si continuábamos con Clash en un grupo potencialmente inestable, ya nos imaginábamos que los problemas de los contenedores eran una parte importante del asunto, pero todavía no entendíamos cuál era el tráfico exactamente. Aunque el problema no tenía nada que ver con Clash, decidimos retrasarlo una semana para asegurarnos de proteger la experiencia de Clash. Queremos pedir disculpas por los problemas que haya podido causar esto y os aseguramos que tenemos soluciones para todos los aspectos que han tomado parte.

Hemos corregido el código que hacía que se enviasen peticiones en mal estado y, por si tenemos problemas similares en el futuro, hemos cambiado la forma en la que trabaja el mecanismo de reintento para evitar que cause grandes subidas. La actualización del software de los contenedores ya ha terminado en todos los grupos. Tenemos planes fijos para mover los servicios de edge a un sistema de equilibrado que pueda repartirlos a través de los grupos. Hasta que dichos planes estén en marcha, hemos activado alertas para que el teléfono de alguien se convierta en una máquina chillona hasta que la carga se redistribuya manualmente.
Estamos seguros de que, dejando atrás todas estas causas, este problema no volverá a ocurrir. No obstante, evolucionamos constantemente el juego y sus sistemas de soporte, por lo que situaciones como esta siempre pueden ocurrir. Nos comprometemos a restaurar los servicios lo antes posible cuando ocurran. Gracias por llegar hasta el final. Si este tipo de contenido os llama la atención, podéis echarle un vistazo a más artículos sobre la tecnología de League of Legends en nuestro blog de tecnología. ¡Nos vemos en la Grieta!