
Rapport d'incident : pannes récentes en Europe et au Brésil
Bonjour à tous, ici Brian « Penrif » Bossé du département de technologie de League of Legends. Je suis ici pour vous parler des problèmes techniques ayant récemment entraîné des pannes sur les serveurs EU Ouest, EU Nord & Est et Brésil, vers fin février. Je vais un peu entrer dans les détails techniques, mais si vous êtes curieux de savoir ce qui a causé ces pannes et comment nous les avons résolues, suivez-moi dans ce périple rempli de graphiques et de vocabulaire informatique !
Posons le décor
Le premier symptôme qui a attiré l'attention de notre Centre d'opérations du réseau est la chute considérable du nombre de lancement des parties de League.
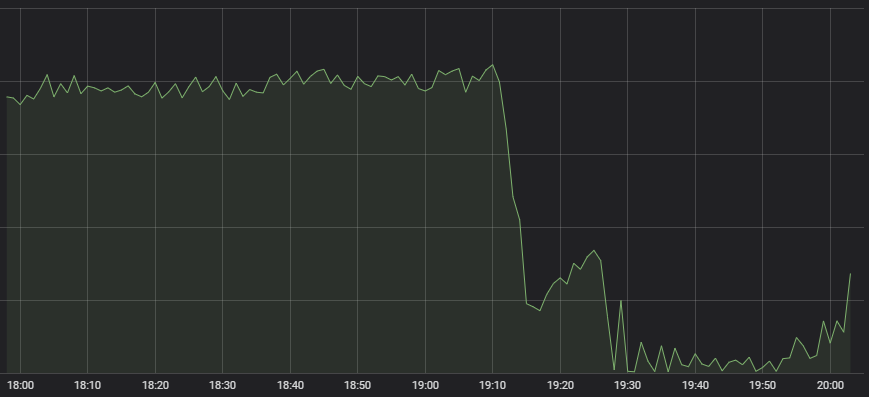
Comportement anormal
Il y a beaucoup de systèmes qui entrent en compte lors de la création d'une partie, que ce soit du matchmaking au chargement même de la partie sur le serveur. C'est pourquoi il est difficile de savoir immédiatement d'où vient la panne. Lorsque nous avons demandé à nos experts d'examiner chacun de ces systèmes pour identifier le problème, ils ont tous indiqué que le serveur avait l'air stable, mais qu'il y avait très peu de trafic entrant. Un matchmaker n'a pas grand-chose à faire, si peu de personnes cherchent une partie.
Tout cela indiquait donc un problème du système qui ne parvenait pas à envoyer le trafic lié à nos joueurs vers notre système interne. Des mesures nous ont indiqué des problèmes majeurs dans cette zone :
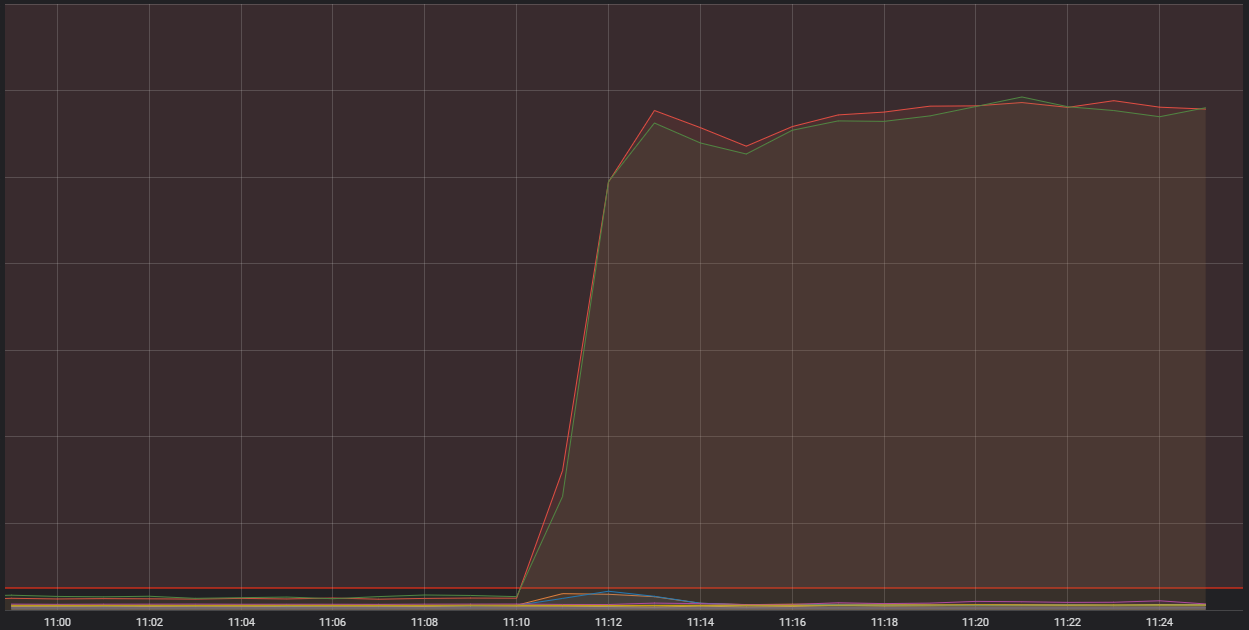
La ligne rouge horizontale tout en bas est ce qui a lancé l'alerte rouge
Ce que vous voyez ici est le nombre de connexions entrantes de l'un de nos hébergeurs de conteneurs. Ce sont des ordinateurs uniques et performants qui font tourner plusieurs applications plus petites (les fameux « conteneurs ») qui constituent le système global de League. Deux de ces hébergeurs subissent bien plus de connexions que la normale. Pour comprendre pourquoi, nous devons parler d'un type de conteneur particulier qui a une fonction dite « d'edge ».
Un problème d'edge
Les processus edge s'occupent de recevoir le trafic issu d'internet, de le filtrer puis de le rediriger vers le service backend approprié. Grossièrement, ils prennent la pile de déchets en provenance de l'internet public et ne laissent qu'un flux de données propre qui peut être traité en toute tranquillité. Comme vous pouvez l'imaginer, les processus edge traitent beaucoup de trafic, mais ne doivent pas subir régulièrement le genre de pics que nous avons observés durant ces événements. Il y a donc trois facteurs qui ont mené à ce problème. Chacun d'entre eux sera traité dans une partie.
Comment tout a commencé
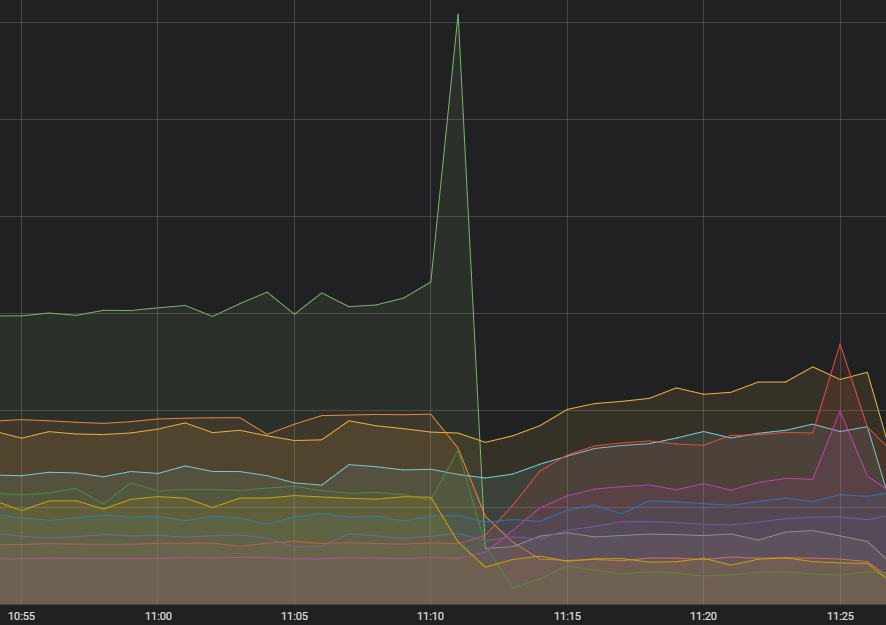
D'abord, il y a eu cette première étincelle, une quantité excessive de requêtes sur un service. Depuis plusieurs mois, nous avons remarqué une augmentation de l'inconstance des fréquences de ce service, mais jusqu'ici, ça ne semblait pas avoir d'impact et les systèmes en amont semblaient le gérer assez bien. Diagnostiquer quelque chose qui n'affectait personne n'était pas notre première priorité active, mais nous ne l'avons pas oublié pour autant. Nous savons désormais de quoi il s'agit. Il y avait une erreur dans la création des requêtes qui, dans certains cas, entraînait un échec constant et donc une nouvelle tentative.
Fuite des conteneurs
Nous avions conscience d'un problème au niveau de l'interaction entre notre système de conteneurs et la version du système d'exploitation utilisée. Le problème impliquait une fuite de mémoire à l'intérieur du système d'exploitation qui, au bout d'un moment, pouvait affecter des activités essentielles du système. Avant cet événement, nous n'avons jamais dû faire face à cette éventualité, mais nous avions déjà effectué des mises à niveau d'environ 60 % de la flotte de conteneurs de Riot. Malheureusement, la mise à jour n'était pas encore terminée pour ceux d'Europe et d'Amérique latine.
Et un peu de malchance
Et enfin, nous avons manqué de chance. Nous utilisons une sorte de programme qui permet de faire tenir plusieurs groupes de conteneurs dans un seul ordinateur hôte. Certaines contraintes sont déjà préprogrammées pour séparer ces services edge, qui sont denses, les uns des autres à l'intérieur de l'ensemble de conteneurs d'un même shard. Cependant, nous ne pouvions pas contrôler si les services edge de différents shards atterrissaient sur le même ordinateur. Les services edge du serveur EU Ouest pouvaient donc se retrouver avec ceux du serveur EU Nord & Est. Cette multiplication de chargements sur une seule machine a été le facteur aggravant qui a conduit les deux précédents problèmes à un incident majeur.
Lors de toutes nos pannes, les conteneurs edge d'au moins trois shards se sont retrouvés sur un seul hôte. Avec ce pic de trafic provoqué par les requêtes défectueuses, ces multiples shards atterrissant dans le même hôte et la fuite de mémoire du système d'exploitation qui rendait la machine non opérationnelle, nous avons subi une perte de l'intégrité du shard et donc une panne importante.
Impact et résolution
C'est souvent assez difficile d'identifier ce genre de problème et de trouver des causes isolées. Lorsqu'il a fallu prendre la décision de maintenir ou non Clash sur un service potentiellement instable, nous nous doutions que les problèmes de conteneur étaient un aspect important de cet événement, mais nous ne savions pas encore quel était l'état du trafic. Même si Clash n'est pas seul responsable du problème, nous avons décidé de décaler le tournoi d'une semaine pour nous assurer que l'expérience soit optimale. Je m'excuse pour les perturbations causées par ces événements et j'aimerais vous assurer que nous sommes en train de corriger chaque aspect de ce problème.

Le code qui entraînait des requêtes erronées a été corrigé, et pour empêcher de potentiels problèmes similaires à l'avenir, nous avons changé le fonctionnement du mécanisme des nouvelles tentatives pour empêcher de nouveaux pics disproportionnés. La mise à niveau de notre logiciel de traitement de conteneurs a été effectuée sur tous nos shards. Nous avons des plans concrets pour déplacer les services edge vers un système d'équilibrage capable de les transmettre à travers plusieurs shards. En attendant que tout ça soit réalisé, nous avons mis en place un système d'alerte pour que le téléphone de quelqu'un ne cesse de sonner jusqu'à ce que la charge de travail soit redistribuée.
Nous sommes confiants qu'avec tous ces soucis désormais derrière nous, ce problème précis ne se reproduira pas. Ceci étant dit, nous continuons constamment d'améliorer le jeu et ses systèmes, c'est pourquoi des situations similaires peuvent toujours survenir. Lorsque c'est le cas, soyez assurés que nous faisons tout notre possible pour restaurer le service aussi vite que possible. Merci d'avoir tenu jusqu'ici. Si ce genre de contenu éveille votre curiosité, n'hésitez pas à découvrir nos articles traitant plus en profondeur de la technologie de League dans notre TechBlog. Dans tous les cas, je vous dis à bientôt dans la Faille !