
Relatório de ocorrência: Quedas - Brasil e Europa
Olá, pessoal, aqui é o Brian "Penrif" Bossé, do departamento de Tecnologia do League of Legends. Vim compartilhar detalhes sobre os problemas técnicos que causaram quedas imprevistas recentemente no BR, EUW e EUNE no fim de fevereiro. Vou falar umas coisas de nerd hoje, mas, se estiverem curiosos sobre os detalhes por trás das quedas e o que fizemos para resolvê-las, venham comigo nessa jornada de computadores e gráficos!
Descrevendo o cenário
O primeiro sintoma que chamou a atenção do nosso atento Centro de Operações de Rede foi que o número de partidas do LoL começou a cair drasticamente.
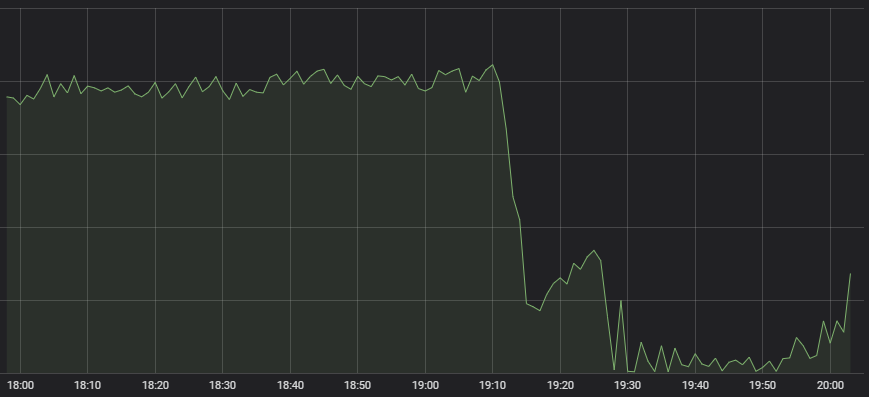
Comportamento atípico
Vários sistemas fazem parte da criação de uma partida bem-sucedida, desde o gerenciamento até a distribuição de carregamento e, então, a partida em si, e não fica imediatamente claro onde está o problema em caso de um sintoma desses. Quando trouxemos os especialistas em cada um desses sistemas para fazer essa avaliação, todos indicaram que a integridade do serviço parecia boa, mas havia pouco tráfego de entrada. Não há muito a se fazer em caso de um gerenciamento com poucas pessoas querendo entrar numa partida.
Então, tudo isso indicava que estávamos enfrentando um problema sistêmico para receber o tráfego de jogadores. As métricas nos mostravam problemas graves nessa área:
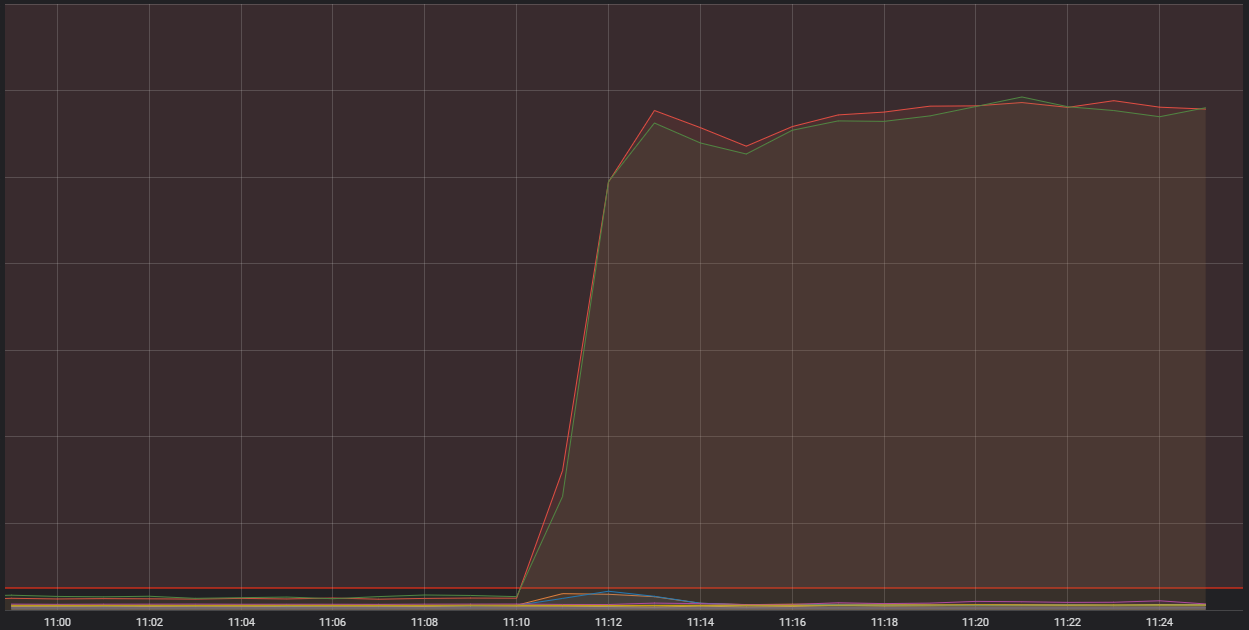
A linha vermelha horizontal percorrendo a parte inferior foi o que disparou nossos alarmes
Aqui, vemos o número de conexões entrando em um dos nossos hosts de contêiner genéricos. São computadores únicos de alta capacidade que rodam uma série de aplicativos menores (na linguagem técnica, contêineres) que abrangem o sistema geral que roda o LoL. Dois desses contêineres estavam recebendo muito mais conexões do que o aceitável. Para entender o motivo, precisamos falar mais sobre um tipo específico de contêiner que realiza uma função de "ponta" (ou o que chamamos de "edge").
Bem na ponta
Processos de ponta têm a tarefa de receber o tráfego da internet, filtrá-lo e enviá-lo para o serviço de back-end apropriado. Eles recebem toda a pilha de lixo que é a internet pública e deixam apenas um fluxo limpo de bytes para que o restante do processamento seja tranquilo. Como podem imaginar, processos de ponta passam por muito tráfego, mas os picos que vimos durante esses eventos não deveriam acontecer. Há três fatores que se alinharam para criar essa situação. Farei uma seção para cada um deles e, no fim, falarei de todos eles juntos.
E assim começa...
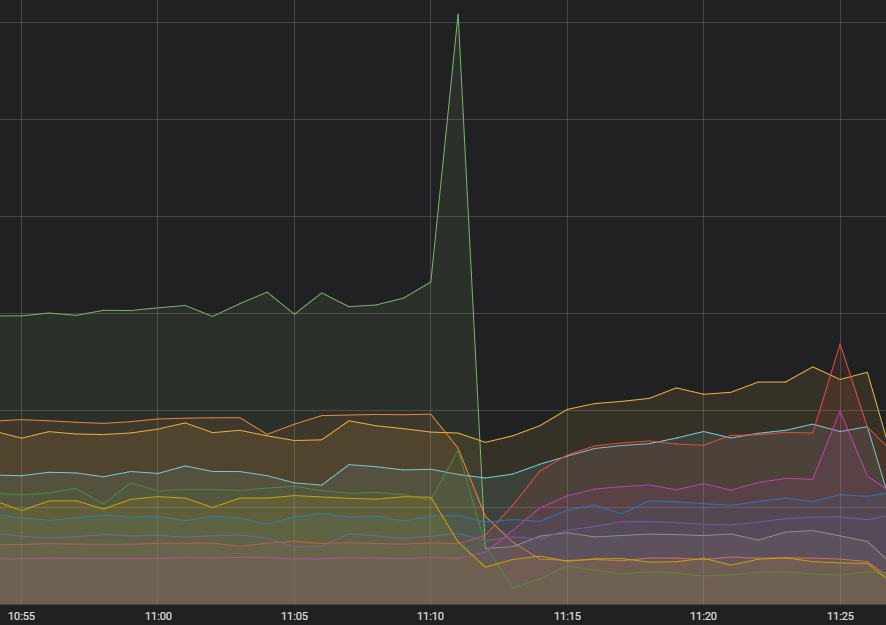
Primeiro, a fagulha que começou o incêndio: uma quantidade incomum de solicitações de um serviço. Por alguns meses, notamos um aumento na volatilidade da frequência de chamadas para aquele serviço, mas isso não pareceu ter impacto algum e todos os sistemas upstream pareciam estar lidando bem com isso. Diagnosticar algo que não prejudicava ninguém não parecia ser uma prioridade, mas mantivemos isso em mente. Agora, já diagnosticamos o que aconteceu: ocorreu um erro em como a solicitação era feita, o que, em certos casos, causava uma falha constante e, consequentemente, novas tentativas.
Vazamento nos contêineres
Tínhamos um problema já conhecido relacionado a uma interação do nosso sistema de contêiner com a versão do sistema operacional em uso. O problema envolvia um vazamento de memória no interior do sistema operacional, o que poderia interromper funções críticas do sistema se não fosse resolvido logo. Antes desse evento, nunca tínhamos visto essa manifestação, mas já havíamos atualizado cerca de 60% da frota de contêineres da Riot. Infelizmente, a atualização dos clusters da Europa e da América Latina ainda estava em progresso.
A sorte faz toda a diferença
Conclusão: demos azar. Utilizamos um software para agrupar os contêineres em grupos que pudessem ser colocados em um único host central. Ele tinha restrições programadas para manter esses serviços de ponta mais pesados separados uns dos outros dentro do conjunto de contêineres da mesma região. No entanto, não podíamos controlar se os serviços de ponta de regiões diferentes cairiam no mesmo computador, então os serviços de ponta da EUW poderiam acabar ao lado dos da EUNE. Essa multiplicação de cargas em uma única máquina foi o que causou e aumentou o choque entre os dois problemas anteriores.
Em todas as quedas, os contêineres de ponta de pelo menos três regiões foram colocados em um único host. Com o tráfego das solicitações anormais (amplificado por ter várias regiões no mesmo host), mais o vazamento de memória do sistema operacional deixando a máquina não funcional, tivemos um colapso de integridade da região e uma taxa de queda significativa.
Impactos e solução
Resolver esse tipo de problema e encontrar as causas isoladas costuma exigir bastante esforço. Quando tivemos que decidir entre continuar ou não com o Clash tendo um cluster potencialmente instável, suspeitamos que os problemas do contêiner eram uma parte essencial da questão, mas ainda não tínhamos certeza quanto ao que estava acontecendo com o tráfego. Mesmo que o problema não tenha sido causado pelo Clash, decidimos atrasá-lo em uma semana para garantir que a experiência fosse protegida. Peço desculpas sinceras pela interrupção que esses eventos causaram, e garanto a vocês que teremos soluções para todos os aspectos envolvidos.

O código que causava o envio das solicitações problemáticas foi corrigido e, caso tenhamos problemas semelhantes no futuro, já mudamos a forma como o mecanismo de novas tentativas funciona para evitar o surgimento de picos. A atualização do software de contêineres foi concluída em todas as regiões. Temos planos concretos para mover os serviços de ponta para um sistema de balanceamento que possa acomodar a propagação deles entre regiões. Até que esses planos sejam executados, temos alertas preparados para que o telefone de alguém vire uma buzina ensurdecedora até que o carregamento seja redistribuído manualmente.
Acreditamos que, com tantas causas diferentes por trás desse problema, ele não ocorrerá novamente. Dito isso, seguimos aprimorando constantemente o jogo e seus sistemas de suporte, e situações como essa sempre são uma possibilidade. No entanto, nós nos comprometemos a restaurar o serviço o mais rápido possível caso elas aconteçam. Obrigado por lerem até o fim. Se esse é o tipo de conteúdo que gostam de ler, temos artigos mais aprofundados sobre a tecnologia do LoL no nosso TechBlog (somente em inglês) . A gente se vê no Rift!