

Raport de incident: probleme recente în EU și BR
Salutare, sunt Brian ''Penrif'' Bossé din departamentul tehnologic pentru League of Legends. Vă voi oferi câteva detalii despre problemele tehnice care au provocat întreruperile recente din EUW, EUNE și BR de la sfârșitul lunii februarie. Voi intra în niște detalii tehnice aici, dar, dacă sunteți curioși să aflați ce anume a provocat problemele respective și ce am făcut pentru a le remedia, haideți alături de mine într-o aventură cu computere și grafice!
Situația în ansamblu
Primul simptom care a ajuns în atenția vigilentului centru de operații de rețea a fost reducerea drastică a numărului de meciuri de LoL care începeau.
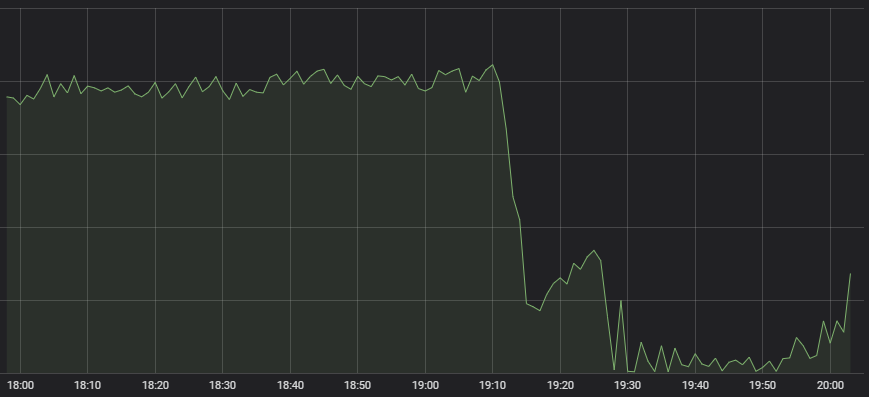
Nu este un comportament obișnuit
Există o mulțime de sisteme care contribuie la crearea cu succes a unui meci, de la sistemul de alcătuire a echipei până la distribuirea sarcinii pe serverul de joc. Așa că nu este clar imediat unde se află problema pe baza unui astfel de simptom. Când am reunit experții în aceste sisteme pentru a stabili cauza, toți au spus că serviciul lor arată în regulă, doar că la aceste servicii ajungea foarte puțin trafic. Un sistem de alcătuire a echipei cu un lot mic de jucători care solicită un meci nu prea are ce face.
Prin urmare, aveam de-a face cu o problemă de sistem care împiedica traficul de jucători să ajungă în backend. Valorile ne indicau câteva probleme majore în acea zonă:
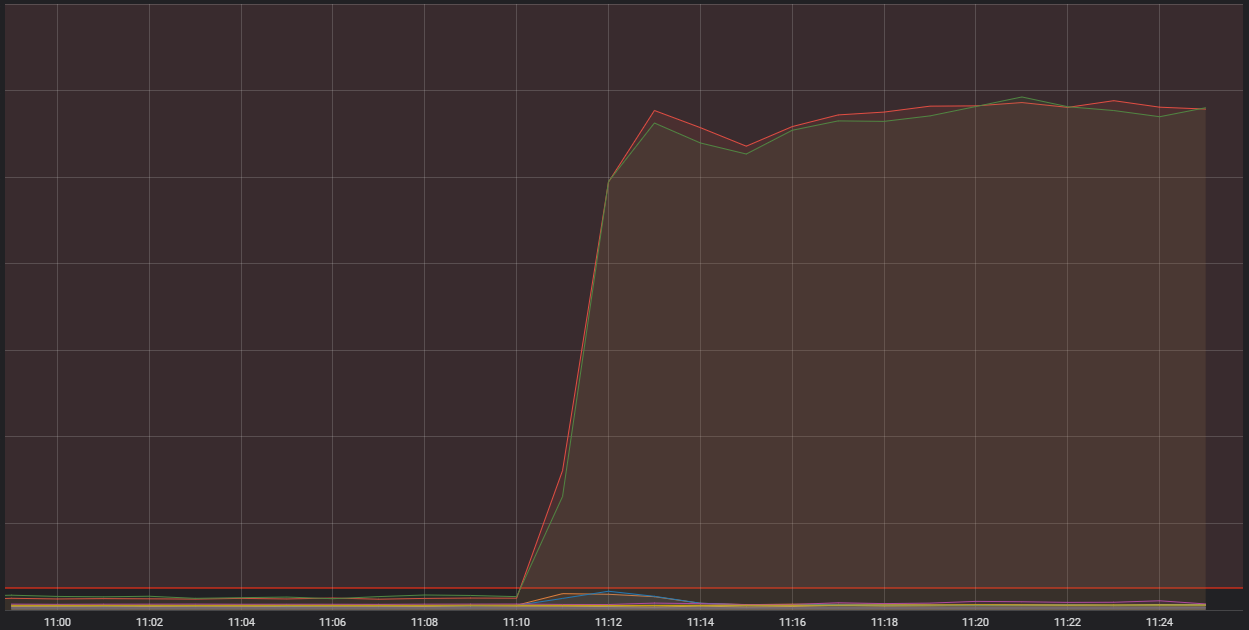
Linia orizontală roșie din partea de jos indică pragul pentru declanșarea alarmelor
Ceea ce vedem aici este numărul de conexiuni de intrare către una dintre gazdele noastre container generice. Acestea reprezintă computere foarte capabile care rulează o serie de aplicații mai mici – pe scurt, containere – care alcătuiesc sistemul general care rulează LoL. Două dintre acele gazde primesc semnificativ mai multe conexiuni decât este acceptabil. Pentru a înțelege motivul, trebuie să discutăm despre un anumit tip de container, unul care efectuează o funcție ''edge''.
Viața pe muchie
Procesele ''edge'' au sarcina de a prelua traficul de pe internet, de a-l filtra și de a-l transfera către serviciul adecvat din backend. Acestea elimină datele irelevante reprezentate de internetul public și lasă să treacă doar un șir curat de biți, pe care celelalte sisteme îi pot procesa în liniște. După cum vă puteți imagina, procesele ''edge'' au de-a face cu mult trafic, dar nu ar trebui să se confrunte în mod obișnuit cu valori atât de ridicate precum cele observate în timpul acestor evenimente. Există trei factori care, împreună, creează această situație; voi discuta despre fiecare în parte în câte o secțiune, apoi despre toți trei.
Începutul
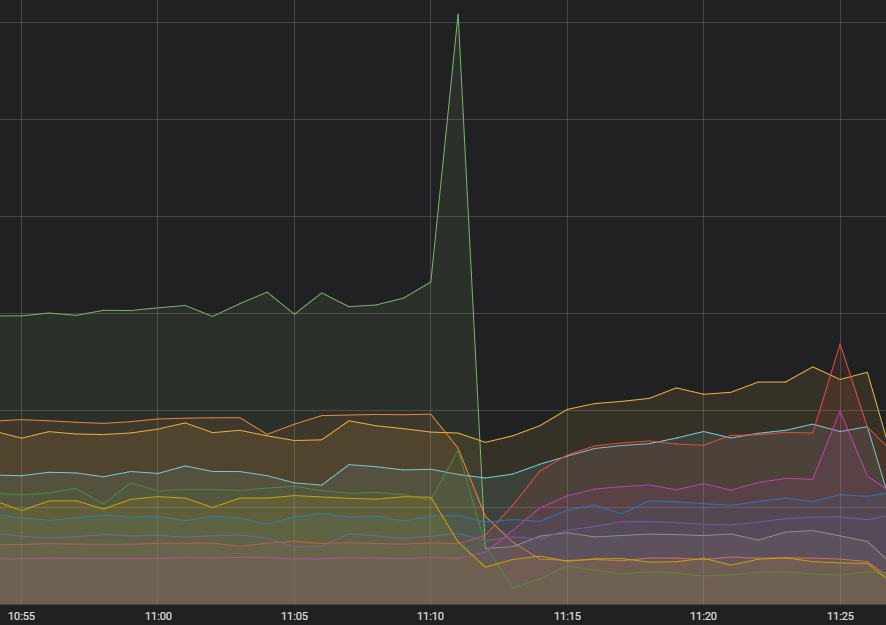
Mai întâi, scânteia care a declanșat cascada – o cantitate nerezonabilă de solicitări către un singur serviciu. Timp de câteva luni, am observat o creștere în volatilitatea frecvenței de apel orientată către acel serviciu, dar nu a părut să aibă vreun impact, iar toate sistemele în amonte s-au descurcat bine. Diagnosticarea unui fenomen care nu influențează negativ pe nimeni nu reprezintă o prioritate pentru un efort activ, dar am ținut cont de acest lucru. Totuși, l-am diagnosticat acum; exista o eroare în modul în care era creată solicitarea, ceea ce în anumite situații ducea la eșecul constant al acesteia – și la reîncercarea constantă.
Containere cu o fisură
Aveam o problemă cunoscută care implica o interacțiune dintre sistemul de containere și versiunea sistemului de operare folosită. Problema era o scurgere de memorie în interiorul sistemului de operare, care putea opri funcții critice ale sistemului dacă era lăsată să se acumuleze în timp. Înaintea acestui eveniment, nu o mai văzusem manifestată, dar oricum făcusem deja actualizări pentru aproximativ 60% dintre containerele Riot. Din păcate, actualizarea pentru clusterele din Europa și America Latină era încă în desfășurare.
Norocul contează
Și, în cele din urmă, am avut ghinion. Folosim un software pentru a grupa containerele în seturi, care pot încăpea pe un computer gazdă. Are constrângeri programate pentru a separa între ele aceste servicii ''edge'' care folosesc mult rețeaua, în cadrul aceluiași set de containere de pe server. Totuși, nu am putut controla dacă serviciile ''edge'' de pe servere diferite pot ajunge pe același computer, așa că serviciile ''edge'' de pe EUW ar putea ajunge chiar lângă serviciile ''edge'' de pe EUNE. Acea multiplicare a sarcinii pe un singur computer a fost amplificatorul care a transformat cele două probleme anterioare într-un incident major.
În toate cazurile, containerele ''edge'' de pe cel puțin trei servere au ajuns pe o singură gazdă. Cu o abundență de trafic de la solicitările problematice, amplificată de faptul că traficul de pe mai multe servere ajungea pe aceeași gazdă, urmată de scurgerea de memorie a sistemului de operare care aducea computerul într-o stare de nefuncționare, s-a ajuns la o avarie a integrității serverului și la o indisponibilitate semnificativă.
Impact și rezolvare
În general, este nevoie de efort considerabil pentru a înțelege acest timp de problemă și a găsi cauze izolate. Când a trebuit să decidem dacă vom continua turneul Clash în condițiile unui cluster potențial instabil, aveam suspiciuni că problemele containerelor erau o parte-cheie a situației, dar nu știam încă exact cu ce trafic aveam de-a face. Chiar dacă problema nu era deloc legată de Clash, am luat decizia de a amâna turneul cu o săptămână, pentru a ne asigura că experiența din Clash rămâne intactă. Îmi pare sincer rău pentru neplăcerile cauzate de aceste evenimente și vreau să vă asigur că avem soluții pentru fiecare element care a jucat un rol în această situație.

Codul care ducea la trimiterea cererilor problematice a fost corectat și, în caz că vom mai avea probleme similare în viitor, am modificat modul de funcționare al sistemului de reîncercare, pentru a evita formarea de acumulări serioase. Actualizarea software-ului containerelor a fost finalizată pe toate serverele. Avem planuri concrete de a muta serviciile ''edge'' într-un sistem de echilibrare, care poate gestiona distribuirea lor între servere. Până la implementarea acelor planuri, avem un sistem de alertă în funcțiune, astfel încât telefonul cuiva se transformă într-o alarmă zgomotoasă până la redistribuirea manuală a sarcinii.
Suntem încrezători că am depășit toate aceste cauze diferite și că această problemă nu se va mai repeta. Acestea fiind spuse, vom continua să dezvoltăm jocul și sistemele de la baza acestuia, iar situații similare sunt mereu posibile. Suntem hotărâți să restabilim serviciul cât de repede posibil atunci când se întâmplă asta. Vă mulțumesc că ați ajuns până la sfârșit; dacă acest tip de conținut vă stârnește curiozitatea, puteți citi mai multe articole pe teme tehnologice din LoL pe blogul dezvoltatorilor. În orice caz, ne vedem în Rift.
